





BERT( Bidirectional Encoder Representations from Transformers)
Google AI 双方向Transformer で言語モデルを事前学習することで汎用性を獲得し、転移学習させると、8つのベンチマークタスクでSOTAを達成。
様々な種類の自然言語処理に対して汎用的に使える自然言語処理モデルです。 BERTは事前学習モデルであり 事前学習したモデル を既存のタスク実行モデル に合成することで、 そのモデルの精度を向上させることができます。
この合成する作業をファインチューニング と呼びます。
(State of the Art: 現在最も優れている手法)
ACL/NACCL/EMNLP といった海外の主要な自然言語処理に関する国際会議でも非常に頻繁に取り上げており、更にさまざまタスクでベンチマークを超え続けています。
BERT で 転移 学習 し た モデル は、 少ない データ を 追加 学習 する のみ で 動作 する ので、 モデル 作成 の 手間 が 大幅 削減 さ れ ます。 また、 BERT は ネット 上 に 大量 に ある データ を 用い て 事前 学習 を 行う ため、 自前 で 大量 データ を 作成 する 必要 が ない という 点 でも 優秀 です。 例えば、 Wikipedia の 記事 や SNS の 書込み から 事前 学習 を する こと が でき ます。 BERT は 2018 年 11 月 に Google より 発表 さ れ まし た。

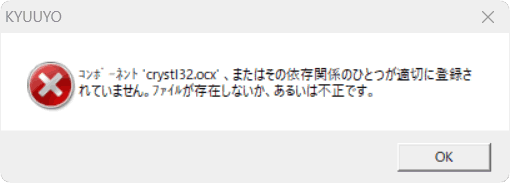
コメント